Introduction
On April 24, the highly anticipated DeepSeek V4 was officially announced with a preview version and open-sourced.
This version features two MoE models, both standardly equipped with a 1 million token context: DeepSeek-V4-Pro with a total of 1.6 trillion parameters and 49 billion active parameters, and DeepSeek-V4-Flash with 284 billion total parameters and 13 billion active parameters.
DeepSeek defines V4 as an infrastructure-level release, focusing on restructuring the cost structure of long contexts to pave the way for the next phase of test-time scaling and long-range agent tasks.
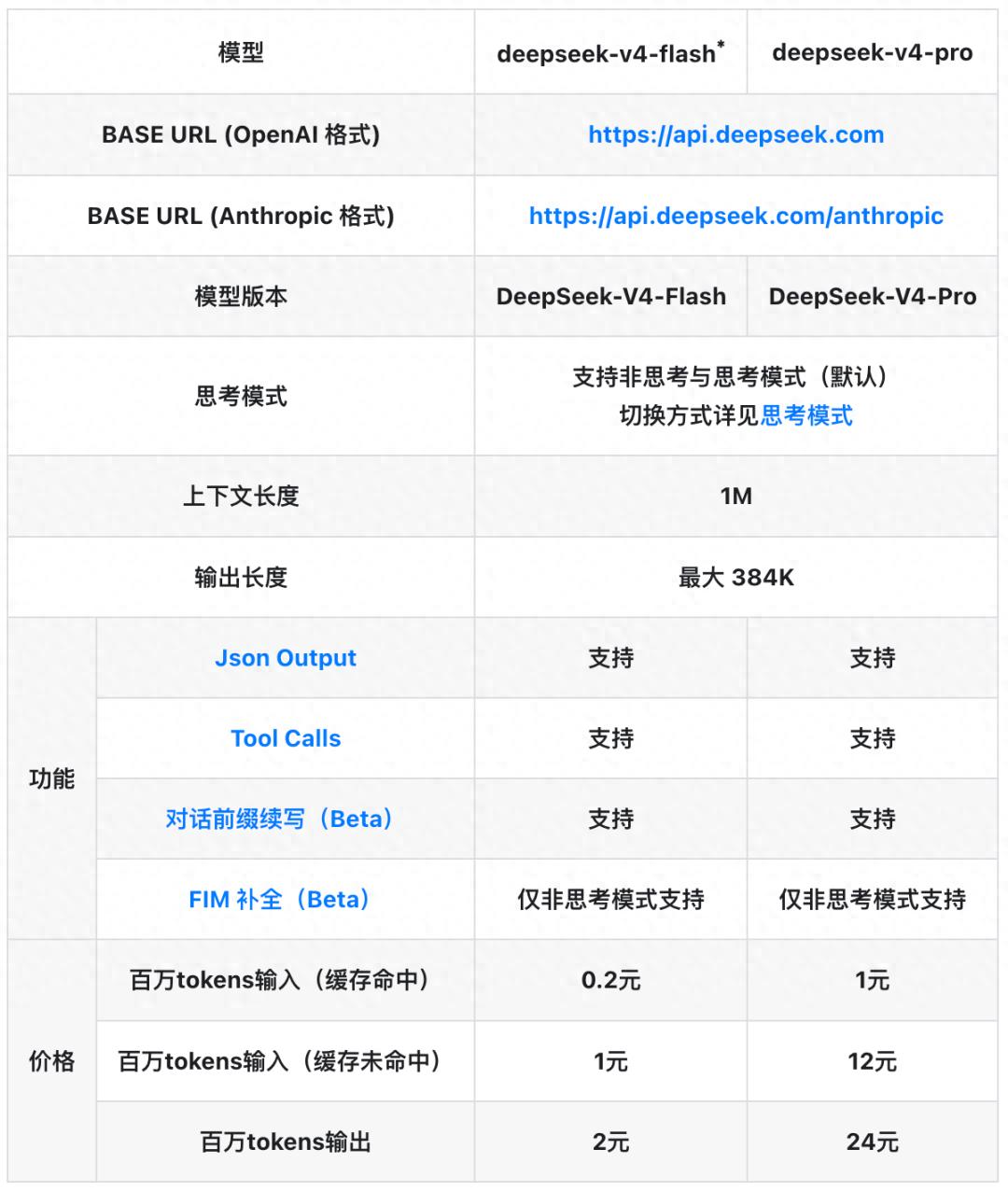
Currently, both the official website and app have launched V4, with the API available for calls.
Two Models, Three Levels of Inference Strength
The most notable aspect of V4 is the significant increase in parameters: 1.6 trillion total parameters and 49 billion active parameters, compared to the previous generation V3.2’s approximately 660 billion total parameters. The parameter count of V4-Pro is 2.4 times greater, while the increase in active parameters is relatively small, from 37 billion to 49 billion. This indicates that V4’s MoE gating network is more sparse, requiring less computational power per token while providing a larger knowledge base.
The 1.6 trillion parameters also surpass Kimi 2.6’s 1 trillion parameters, making it the largest parameter scale among domestic open-source models.
The million-token context is another intuitive upgrade of V4. Starting today, the 1 million token context window is no longer exclusive to the Pro version but standard across all official DeepSeek services, including V4-Flash. Previously, mainstream context windows in the industry ranged from 128K to 256K, with the 1M level being a long-standing advantage of Google Gemini. V4’s update makes this capability a basic configuration.
Combining the 1.6 trillion parameters with the 1M context reveals V4’s technical positioning: utilizing a larger parameter pool to carry more knowledge, controlling inference costs with sparser activations, and transforming long text processing from a premium feature into infrastructure.
Each model in the V4 series offers three levels of inference strength: Non-think direct output mode, Think High for regular deep thinking, and Think Max for maximum depth of thought.
The design goal of the Max mode is to extract the model’s upper limits. V4-Pro-Max improved from 34.5 to 37.7 in HLE tests, and from 85.5 to 90.2 in the Apex Shortlist, surpassing flagship models from OpenAI, Anthropic, and Google.
In knowledge and reasoning benchmarks, V4-Pro-Max leads in hard reasoning and programming tasks like Apex Shortlist (90.2%) and Codeforces (Rating 3206), while Gemini-3.1-Pro-High maintains an advantage in general knowledge Q&A tasks like SimpleQA Verified (75.6%) and MMLU-Pro (91.0).
Regarding agent capabilities, the four comparative models scored equally on SWE Verified (80.6%), while DeepSeek excelled in Terminal Bench 2.0 (67.9%) and Toolathlon (51.8%) tests for tool invocation and complex instruction execution.
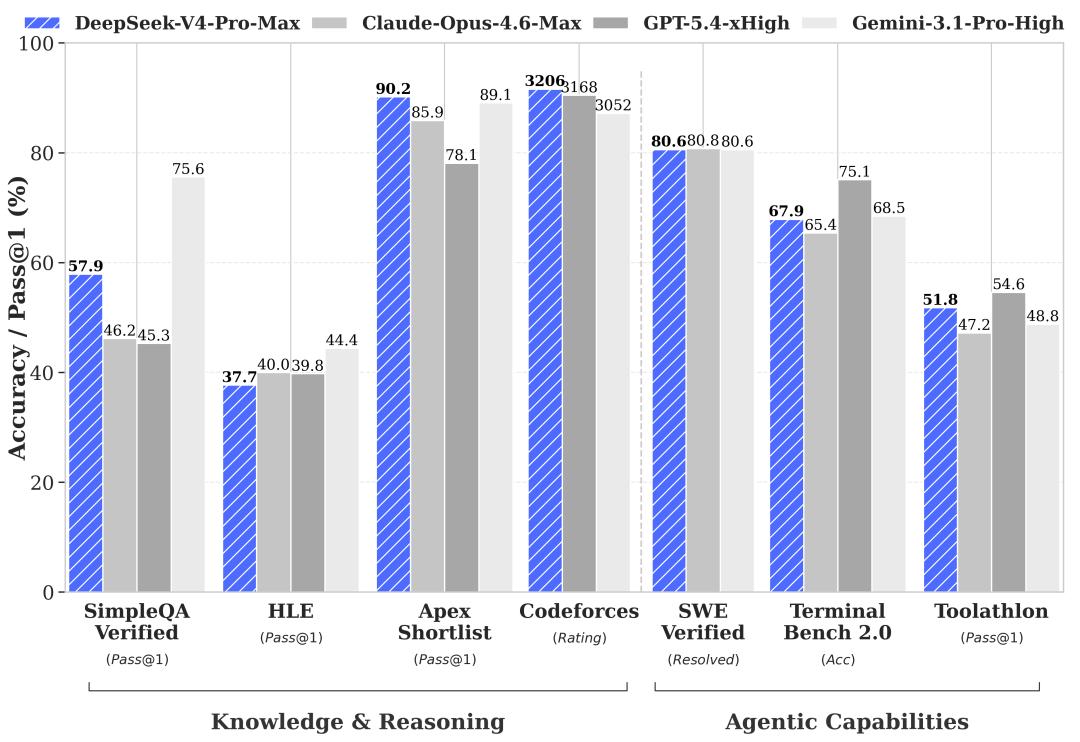
The official positioning of V4-Pro’s agent capabilities states: “User experience surpasses Sonnet 4.5, and delivery quality is close to Opus 4.6 in non-thinking mode, but still lags behind Opus 4.6 in thinking mode.” This indicates that DeepSeek ranks at the top of open-source models in terms of agent capabilities.
According to technical documentation, DeepSeek has already replaced Claude with V4 in actual coding work.
Competitive Pricing
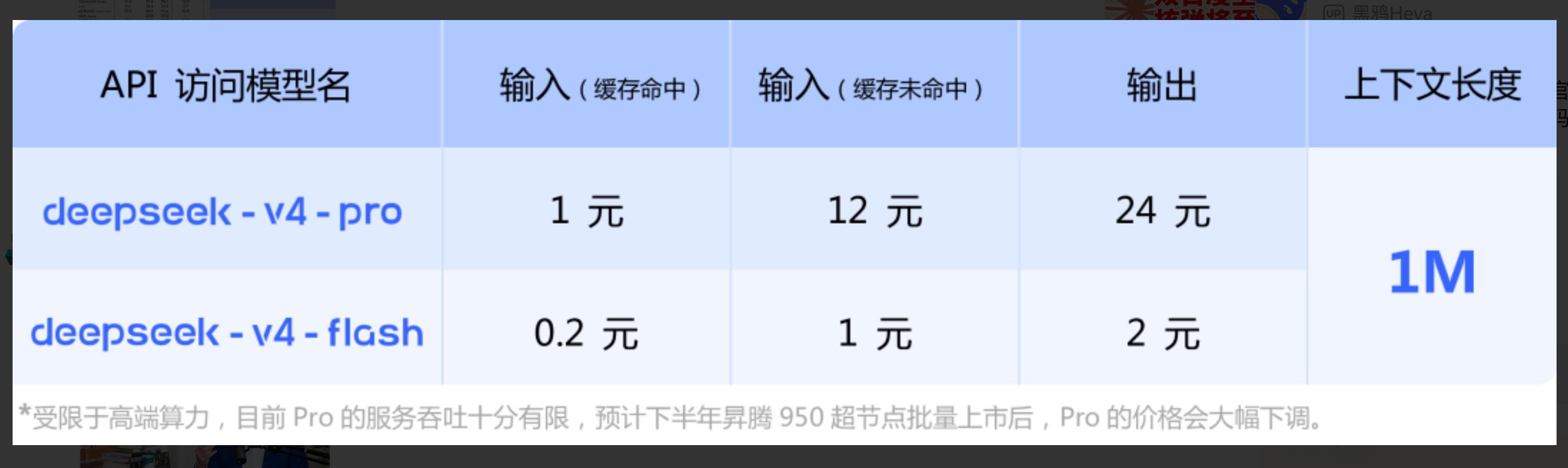
Considering that both models of DeepSeek V4 come with a million-token context, the API pricing, especially for the Flash version, is exceptionally competitive.
V4-Flash has an input price of 1 yuan and an output price of 2 yuan, setting the entry price for million-token models at a floor price, with input dropping to only 0.2 yuan after cache hits. V4-Pro follows a limited supply, performance-first route, with pricing at 12 yuan/24 yuan, constrained by high-end computational capacity, but still offers a high cost-performance ratio.
To provide an intuitive comparison of cost-performance, V4-Flash is compared against domestic and international economic models, while V4-Pro is compared to flagship models.
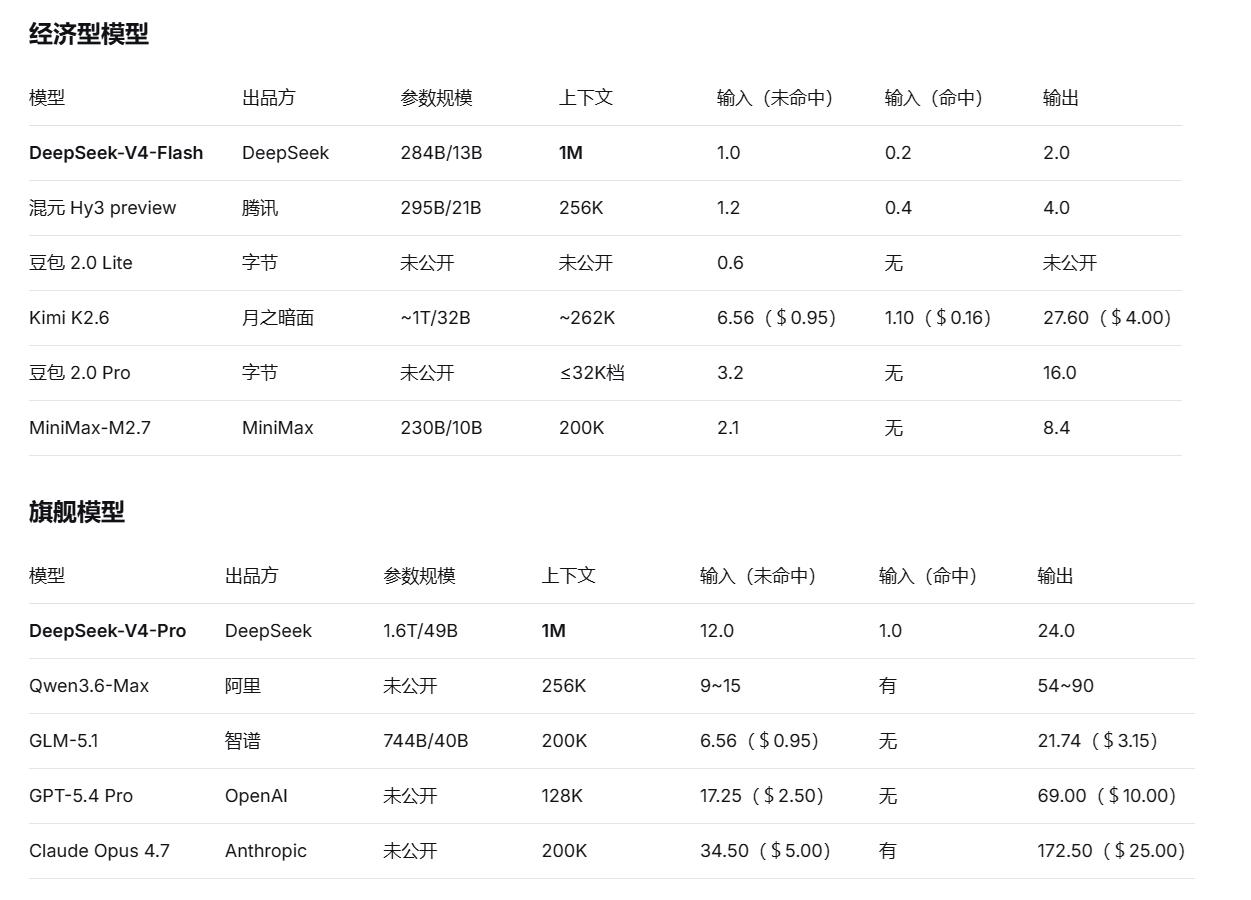
In this comparison, V4-Flash is the only model with standard 1M context, and both input and output prices are the lowest tier. Compared to Tencent’s Hy3 at 1.2 yuan/4.0 yuan, Flash’s output price is only half. Compared to MiniMax-M2.7 at 2.1 yuan/8.4 yuan, Flash is just a quarter. Against Kimi K2.6, Flash’s output price is less than one-fourteenth. Although Byte’s Doubao 2.0 Lite has a lower input price (0.6 yuan), its context length and output price are not disclosed, making a complete cost-performance evaluation difficult.
V4-Pro also shows a clear cost-performance advantage in this flagship comparison. Its output price of 24 yuan is only 27% of Qwen3.6-Max’s upper limit, 35% of GPT-5.4 Pro’s, and 14% of Claude Opus 4.7’s. GLM-5.1’s output price (21.74 yuan) is slightly lower than V4-Pro, but its context is 200K, while V4-Pro is 1M, a fivefold difference. Considering context length, V4-Pro ranks highest in unit token cost-performance among similar flagship models.
Notably, in cache hit scenarios, V4-Pro’s input drops to only 1 yuan, significantly reducing actual costs for high-frequency agent calls and code assistance scenarios.
Moreover, the current pricing of V4-Pro is limited by high-end computational capacity, representing a transitional price rather than a final price. As the Ascend 950 becomes available in large quantities later this year, the price of the Pro version is expected to drop significantly, further widening the price gap with overseas closed-source models. This suggests that DeepSeek’s powerful performance and extreme cost-performance ratio may replicate the impact it had on the U.S. capital and AI market during the release of the R1 model last year.
Optimizing Attention Mechanisms
DeepSeek attributes the improvement in model capabilities to the optimization of the attention mechanism.
In traditional Transformers, the attention mechanism requires each token to compute similarity with all preceding tokens. When the context is expanded from 100K tokens to 1 million, the computational load increases not tenfold, but a hundredfold. This has been the fundamental reason long contexts have been difficult to implement.
V4’s approach is to decompose attention into two types, used alternately. CSA compresses sparse attention by merging every four tokens’ KV caches into a summary, allowing each query to compute attention only on the most relevant top-k summaries. HCA further compresses attention by merging every 128 tokens into one, but applies dense attention to the remaining summaries without sparse selection. The combination of these two attention types, along with a sliding window branch to handle dependencies between adjacent tokens, forms a scheme that combines coarse and fine granularity, sparse and dense.
The effect is directly reflected in the cost curve. Under the 1M token context setting, V4-Pro’s single token inference FLOPs are only 27% of V3.2’s, and KV Cache is only 10%; V4-Flash is even more extreme, at 10% and 7%, respectively.
Viewing V4 within the context of DeepSeek’s technological trajectory over the past two years, the logic is consistent. V2 and V3 focused on parameter sparsity—having a large total parameter count while activating only a small portion for each token. V4 builds on this by introducing context sparsity, with KV compression, top-k selection, and hierarchical compression rates working in synergy. This is the first time DeepSeek has advanced the idea of sparsity into the core structure of Transformers.
In addition to the attention layer, V4 has two other modifications not seen in previous versions. One is upgrading the traditional residual connection to an mHC manifold constraint super connection, providing mathematical constraints for more stable forward and backward propagation in deep networks. The second is replacing most modules’ original AdamW with the Muon optimizer, which converges faster and trains more stably.
Post-training Paradigm Shift: Distilling Multiple Experts into One Model
More noteworthy than the architectural changes is the shift in post-training methods.
Unlike V3.2, which used mixed RL to optimize multiple objectives at once, V4 adopts a two-step approach of “differentiation and then unification.”
In the first step, separate expert models are trained for different domains such as mathematics, code, agents, and instruction following, using high-quality data from each domain for supervised fine-tuning, followed by reinforcement learning with the GRPO algorithm to optimize within their specific tracks. In the second step, a method called On-Policy Distillation is used to merge multiple domain experts back into a unified student model—where the student generates responses and matches them against the output distribution of the expert most knowledgeable about the question, aligning capabilities through logit-level matching.
The engineering difficulty of this process lies in the impracticality of loading multiple trillion-parameter teacher models for online inference simultaneously. DeepSeek’s approach is to unload all teacher weights to distributed storage, caching only the last layer’s hidden state of each teacher, and sorting samples by teacher index during training, ensuring that only one teacher head resides in GPU memory at any given time.
This method circumvents the capability interference issues often seen in traditional mixed RL. V4’s capabilities no longer rely on a single model learning from scratch but instead allow different experts to reach their peak in their respective tracks before integrating them into a single weight set.
Agent capabilities are also a key optimization direction for V4, with the post-training phase elevated to a separate expert direction trained independently alongside mathematics and code. V4 has been adapted for mainstream agent products such as Claude Code, OpenClaw, OpenCode, and CodeBuddy, showing improvements in both coding tasks and document generation tasks.
Several targeted technical improvements have been made. The tool invocation format has shifted from JSON to a special token-based XML structure, reducing escape errors. Cross-iteration inference traces are fully retained in tool invocation scenarios, unlike V3.2, where each round was cleared, allowing the model to maintain a coherent reasoning chain in long-term agent tasks. In terms of training infrastructure, DeepSeek has built a sandbox platform named DSec, capable of concurrently managing hundreds of thousands of sandbox instances in a single cluster, specifically supporting agent reinforcement learning training and evaluation.
Huawei Ascend Comes to Light
In this release, the long-rumored adaptation of DeepSeek to domestic chips has finally surfaced.
In the technical report, section 3.1 explicitly states: “We have verified the fine-grained EP (Expert Parallel) scheme on both NVIDIA GPUs and Huawei Ascend NPUs.” This marks the first time DeepSeek has officially included Huawei Ascend alongside NVIDIA in its hardware verification list.
Observers noted that Ascend CANN will live stream the debut of DeepSeek V4 on the Ascend platform at 4 PM today.
In the pricing table notes, DeepSeek indicated in the official release article: “It is expected that after the large-scale launch of Ascend 950 super nodes in the second half of the year, the price of the Pro version will also be significantly reduced.”
The technical report also disclosed that V4’s MoE expert weights and sparse attention indexers utilize FP4 precision, which is the native supported precision of Huawei’s Ascend 950PR chip released in March. The training-oriented 950DT plan is set to launch in the fourth quarter of this year. On the same day, Ascend CANN officially announced the debut of DeepSeek V4 on the Ascend platform, and Cambricon confirmed that it has completed Day 0 adaptation for V4-Flash and V4-Pro based on the vLLM inference framework, with the code open-sourced.
The current API pricing for V4—Pro input at 12 yuan/million tokens (1 yuan for cache hits), output at 24 yuan, Flash input at 1 yuan (0.2 yuan for cache hits), output at 2 yuan—is a stage pricing constrained by high-end computational capacity. As the Ascend 950 becomes available in large quantities later this year, this pricing line will be redefined.
DeepSeek concluded its release article with a quote from Xunzi: “Do not be tempted by praise, nor fear slander; follow the way and correct oneself.” Despite rumors of its first financing round, DeepSeek maintains a detached yet solid development approach.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.