
This morning, DeepSeek V4 was released, pushing the capabilities of large models to new heights.
With a million-context standard, its performance rivals top closed-source models, and it is the first to adapt to Huawei’s Ascend chips. Each feature can generate a viral headline.
While reviewing the V4 technical report, I noticed a term that many have overlooked: Muon Optimizer.

This term seemed familiar. It turns out that in the recently released Kimi 2.6, the Muon optimizer achieved a twofold efficiency increase under the same training volume and resolved training instability at a trillion-parameter scale.

Last month, Yang Zhiling spent a significant portion of his presentation at NVIDIA GTC 2026 discussing it. Kimi is the first team globally to prove that Muon can be used in training trillion-parameter models. (See APPSO interpretation article link)
Yang Zhiling stated, “Using MuonClip instead of Adam to train Transformer large models yields much better results.” When implemented correctly, token efficiency doubles. In terms of data, this is equivalent to utilizing 100 trillion tokens from 50 trillion.
Now, this technology has appeared in the training scheme of DeepSeek V4.
I revisited the underlying architecture of Kimi K2 and found another interesting detail: it uses the MLA (Multi-head Latent Attention) proposed by DeepSeek-V3.
DeepSeek’s technical report mentions Kimi, while Kimi’s architecture is based on DeepSeek. They are intertwined.
This might be the most surreal scene in China’s AI circle: two open-source twin stars, often compared by outsiders, have long merged at the technical level.
Moreover, such coincidences for Kimi are not new.
Five “Collisions”, Five Turning Points
Including the launches of V4 and K2.6, this marks the fifth “collision” between Kimi and DeepSeek in the past year.
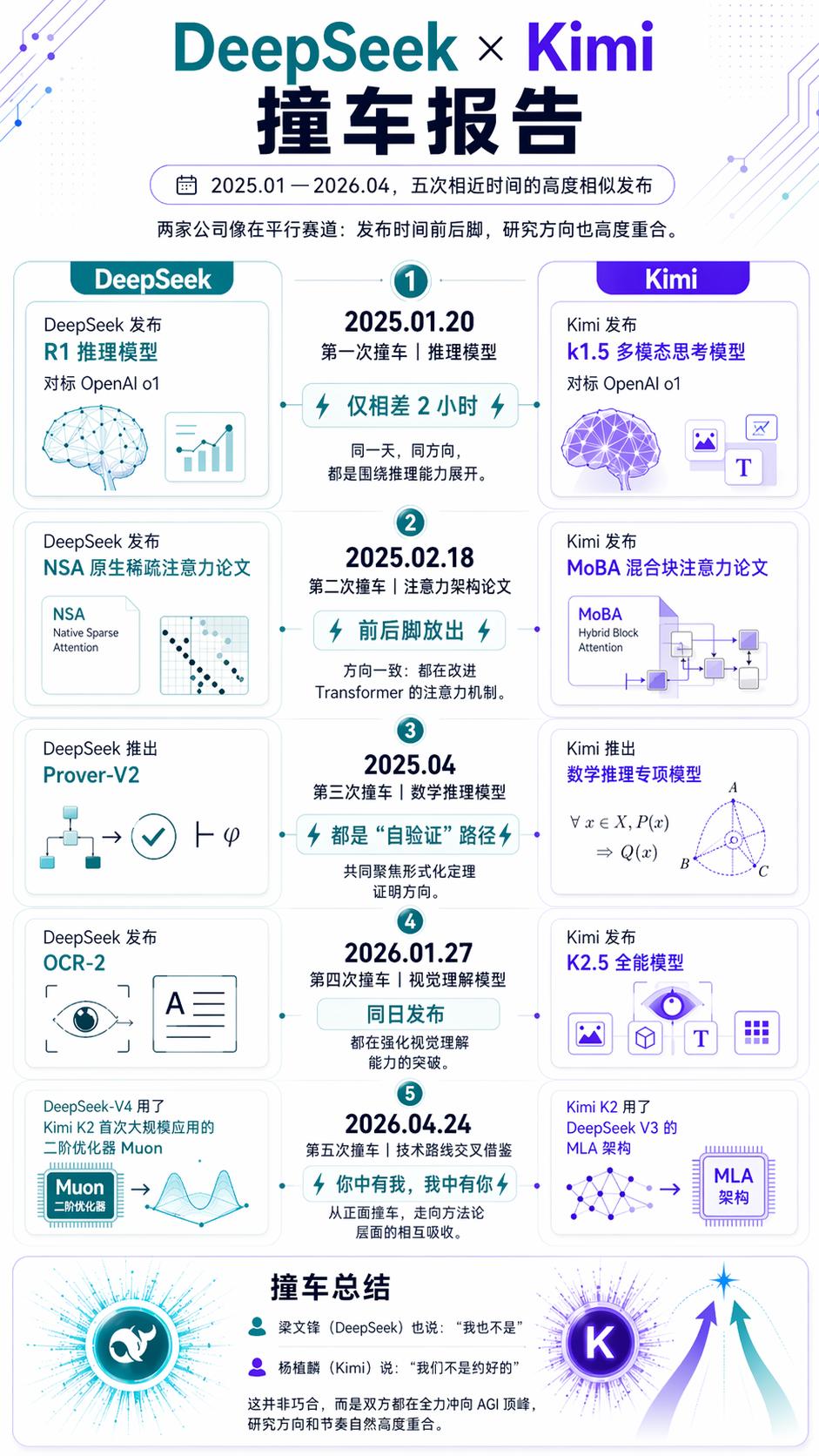
If these five collisions were merely coincidental in timing, that would be one thing. However, examining each release reveals a clear underlying trend: each collision corresponds to a turning point in the AI industry.
The first was the most dramatic. On January 20, 2025, at 8:10 PM, DeepSeek R1 was released and fully open-sourced under the MIT license. Less than two hours later, Kimi k1.5 made its debut.
Both aimed at the same goal: transforming models from “speaking without thinking” to “thinking before speaking,” using reinforcement learning to facilitate Long-CoT reasoning.
After this, China’s open-source efforts fundamentally changed the global AI landscape.
Later, OpenAI pointed out in a paper that Kimi and DeepSeek were the “first to replicate OpenAI-o1 Long-CoT.” Only these two Chinese companies understood what OpenAI was doing and executed it in their own way.

That was the watershed moment when Chinese AI transitioned from being “followers” to “leaders.”
The latest incident occurred today. Within four days, K2.6 introduced SWE-Bench Pro with 58.6% agent cluster parallel programming capability, while V4 established a million-context standard for all services, extending output length to 384K tokens.
Both companies are advancing domestic chip adaptations: V4 will support Huawei Ascend 950 in the second half of the year, while Cambrian has completed Day 0 adaptation; K2.6 supports mixed inference on domestic chips.
Agent capabilities, programming ceilings, million-context, domestic chip adaptation, open-source ecology—everything is in place.
From “learning to think” to “learning to work,” from “modifying Transformers” to “modifying computational foundations,” these five collisions demonstrate that Chinese AI is no longer merely benchmarking OpenAI, gradually reducing reliance on NVIDIA, and forging its own path in open-source.
The Inevitability Behind the Collisions
While the coincidence of release collisions is intriguing, what’s more noteworthy are the inevitabilities behind them.
Let’s return to the Muon in the DeepSeek architecture.
Yang Zhiling discussed a technical challenge during his GTC presentation: when Kimi scaled Muon to a trillion parameters, training instability became a roadblock. The maximum logits exploded beyond 1000, while normal values ranged from 50 to 100.

Loss initially decreased but then exploded, making convergence impossible. Their solution was QK-Clip, which calculated the clipping value for the maximum logit of each attention head, keeping queries and keys within a reasonable range. Training loss remained unaffected, but stability issues vanished.
The K2 model used this technology to complete training, setting a record for the largest Muon training in machine learning history.
In DeepSeek V4’s technical report, Muon is directly included in the training scheme. Most modules use Muon to accelerate convergence, while the embedding layer and prediction head still use AdamW, employing a hybrid approach. This is a direct reference to Kimi’s foundational innovation.

Conversely, Kimi K2’s underlying architecture adopted the MLA proposed by DeepSeek-V3. Multi-head Latent Attention significantly reduces inference costs by compressing KV cache, marking one of V3’s core architectural innovations.
Your paper became my infrastructure, and my innovation became your foundation. This mutual achievement is noted in the citation list.
In Silicon Valley, such occurrences are rare. The technology between OpenAI and Anthropic serves as a “moat,” kept hidden. However, Kimi and DeepSeek have developed a more primitive and healthier relationship: a positive cycle within the open-source community.
Both Kimi and DeepSeek are among the first players in China to open-source trillion-parameter models, both believing in the Scaling Law. In terms of technology, DeepSeek excels in inference models, while Kimi is known for its agent capabilities.
At the foundational architecture level, both are challenging the same set of “ancient” infrastructures. Kimi published a paper on “Attention Residuals,” while DeepSeek implemented mHC residual connections, both modifying the residual connection methods left over from the ResNet era.
In the realm of long text, Kimi explores linear attention (Kimi Linear), while DeepSeek investigates sparse attention (DSA), arriving at the same destination through different paths.
Thus, when they collide, it’s less about coincidence and more about an inevitable convergence towards the same direction.
Using Chinese Chips to Run Chinese Models for the World
On OpenRouter, Kimi and DeepSeek consistently rank as the top two Chinese models in terms of usage.
Cursor has integrated Kimi, while Japan’s Rakuten AI 3.0 is based on DeepSeek. Being “wrapped” by overseas products was a disgrace two years ago; now it’s a badge of honor.
When Meta’s new model Muse Spark was released, Kimi and DeepSeek were compared alongside GPT-4 and Claude in the official blog’s benchmark. At NVIDIA GTC, Jensen Huang showcased the performance of these Chinese models.
Beyond international recognition, the domestic chip line is noteworthy. The H20 chip has been unavailable for a year, and high-end inference chips currently only have domestic options. Both companies are working on the same goal: enabling Chinese models to run on Chinese chips.

Last week, Jensen Huang mentioned in a podcast, “If DeepSeek had released on Huawei’s platform first, it would have been very frightening for us.”
Today, V4 indeed debuted with Huawei Ascend, with the engineering team migrating the entire tech stack from CUDA to Huawei’s CANN framework, implementing everything from the operator library to communication primitives to memory management. V4’s hybrid attention, MoE expert parallelism, and FP4 quantization training were almost entirely reimplemented from scratch. Cambrian also completed Day 0 adaptation for the entire V4 series of vLLM inference, with the code now open-sourced.

Jensen Huang’s words have come true.
Kimi has also paved the way for domestic chips earlier and more deeply. To facilitate domestic chip integration, Kimi introduced two killer features in architectural innovation.
Kimi Linear’s mixed attention architecture combines linear attention layers with full attention layers in a 7:1 ratio, significantly compressing the KV cache size. The test data is striking: under 32K context, the mixed architecture model’s KV throughput is only 4.66 Gbps, while the dense model at the same scale reaches 59.93 Gbps.
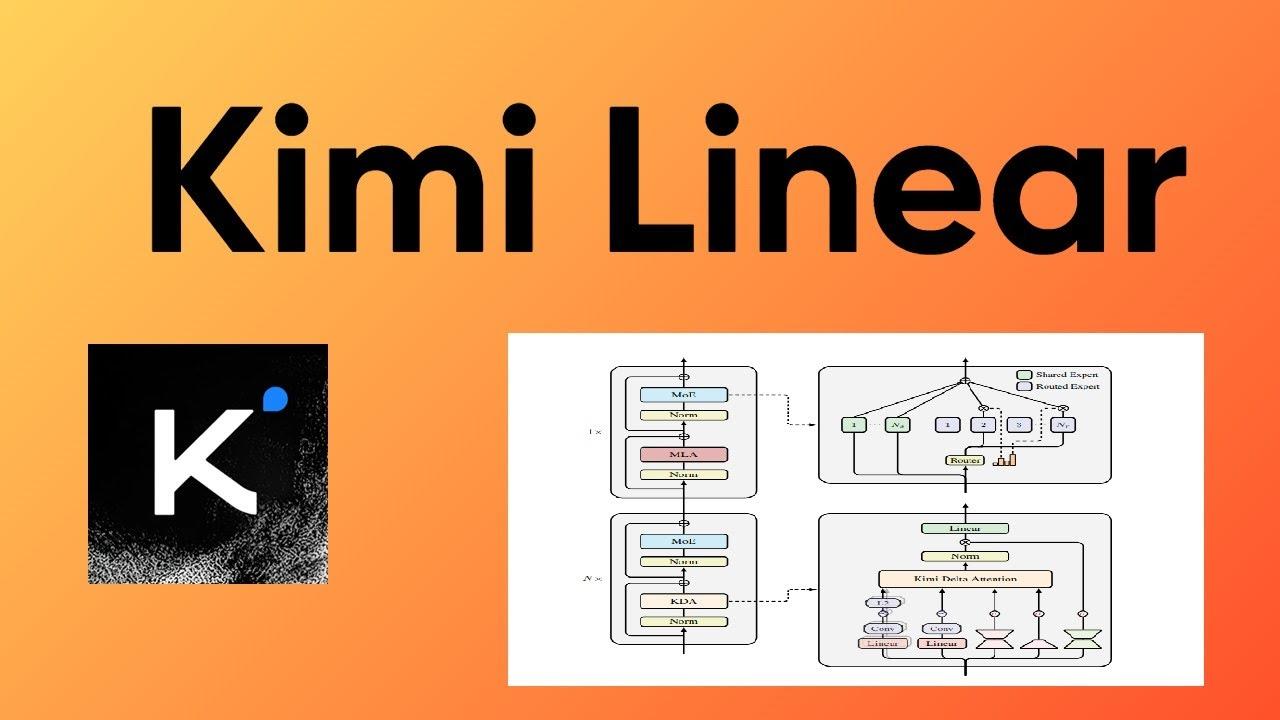
The KV cache transmission requirements have been reduced to levels manageable by ordinary Ethernet, making RDMA high-speed networks optional rather than mandatory.
Building on this, Kimi collaborated with Tsinghua University to publish the PrFaaS (Pre-fill as a Service) paper, decoupling the Prefill and Decode phases of inference and scheduling them across different heterogeneous hardware clusters. The measured throughput increased by 54%, and the first-word latency decreased by 64%.
This solution breaks the premise that “large model inference must be tied to the same high-end GPU”: powerful domestic cards handle Prefill, while bandwidth-strong domestic cards manage Decode, each serving its purpose.
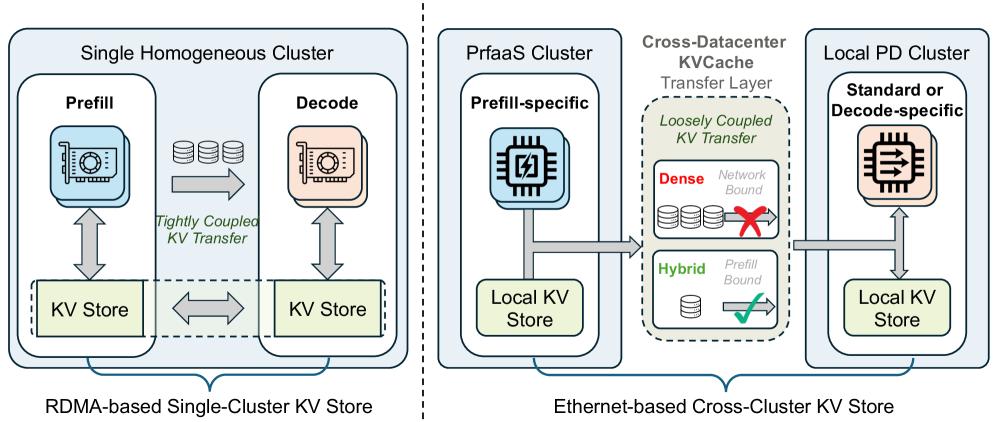
DeepSeek demonstrated with V4 that domestic chips can run flagship models with a trillion parameters, while Kimi proved through architectural innovation that domestic chips can perform well and efficiently.
One approaches from engineering adaptation, the other from architectural design, but the destination is the same: to ensure NVIDIA is no longer the only option.
Previously, the narrative around domestic AI was “using NVIDIA cards to chase OpenAI models.” Now, these twin stars are simultaneously writing a different script: using Chinese chips to run Chinese models, serving developers worldwide.
Your MLA is My Foundation, My Muon is Your Accelerator
Reflecting on the recent whirlwind of updates in the AI industry, we are at a new turning point.
Within the same week, two Chinese teams each released trillion-parameter open-source models, with performance nearing or matching that of top closed-source models in the U.S. This was unimaginable a year ago.
When the price of closed-source models is 50 times that of open-source models, and the open-source camp introduces a new trillion-parameter contender every few months, the balance of competition is subtly shifting.
This is not merely a matter of “winning” or “surpassing.” Closed-source models still have significant advantages in complex reasoning and system reliability, with Opus 4.6’s reasoning patterns remaining the target for V4-Pro to chase. However, the speed, cost advantages, and ecological coverage of the open-source camp are changing the rules of this competition.
In addition to these five collision releases, there is another coincidence between these two companies. Liang Wenfeng is from Zhanjiang, Guangdong, while Yang Zhiling hails from Shantou, Guangdong. These two individuals from Guangdong are supporting half of the global open-source AI landscape.

Liang Wenfeng embodies the philosophy of an engineer, believing in open-source and foundational innovation. The V4 release announcement quotes Xunzi at the end, stating, “Do not be tempted by praise, nor fear slander; follow the path and correct oneself.”

As for Yang Zhiling, he resembles a product scientist, believing that user experience and technological breakthroughs can coexist. During the K2.6 release, he referenced Linus Torvalds, the father of Linux, saying, “Talk is cheap. Show me the code.”
One is classical, the other is a geek. These two distinctly different founders have together positioned China’s open-source models within the global coordinate system.
Your MLA is my foundation, and my Muon is your accelerator. This may also be one of the key reasons China can lead global open-source AI in such a short time.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.