Introduction
The domestic computing power is transitioning from being merely functional to being highly effective, with supernode technology serving as a crucial support in bridging the gap.
On April 24, the preview version of DeepSeek V4 was released. The company disclosed that due to constraints in high-end computing power supply, the V4 Pro version has very limited service throughput. It is expected that with the mass production of Huawei’s Ascend 950 supernodes in the second half of the year, the Pro version’s price will be significantly reduced.
Goldman Sachs pointed out that this statement has dual implications: first, DeepSeek’s cost competitiveness will be further strengthened; second, amid ongoing chip restrictions, the trend of top AI models migrating to domestic computing power is being endorsed by leading players.
Previously, the National Development and Reform Commission also made a rare positive response at a press conference at the end of 2025, stating that “the development of supernode and other cluster interconnection technologies provides a good opportunity for domestic computing power to catch up with international leading levels.”
In this context, Dongfang Securities released an in-depth report on the electronics industry titled “Supernode: The ‘Spear’ of Domestic Computing Power Offensive,” systematically reviewing the technical logic, industrial pattern, and investment opportunities of supernodes. They believe 2026 will be the year of large-scale deployment for domestic supernodes, with the entire supply chain, including exchange chips, server ODM, liquid cooling, and power supply, expected to benefit deeply.
Rising Demand for AI Computing Power: Supernodes as a Necessity
The continuous expansion of model parameters is pushing computing infrastructure into the supernode era.
According to Dongfang Securities’ report, as the MoE (Mixture of Experts) architecture becomes a new trend, model parameters are growing at an annual rate of approximately ten times, having entered the trillion-level stage—Qwen3-Max model parameters exceed 1T, while Wenxin 5.0 has a parameter count of 2.4T.
Correspondingly, the scale of computing clusters is continuously increasing, with tens of thousands of cards now the minimum standard for training large models, and hundreds of thousands of cards becoming the mainstream trend.
 The applicability of Scaling Law has also expanded from pre-training to the entire process of post-training and inference.
The applicability of Scaling Law has also expanded from pre-training to the entire process of post-training and inference.
According to OpenAI, the training computation and inference time increased by an order of magnitude when developing o3, confirming that model performance continues to improve with the number of inference iterations.
DeepSeek stated that it has continuously invested computing power in model post-training reinforcement learning, with V3.2’s post-training investment exceeding 10% of the pre-training cost, achieving inference performance similar to GPT-5-high.
In distributed training architectures, tensor parallelism (TP) and mixture of experts parallelism (EP) have the most significant bandwidth demands.
As the All-to-All communication volume across servers in MoE models surges, traditional Ethernet can no longer bear the TB-level data generated by gradient synchronization for hundreds of billions of models.
Supernodes effectively break through the “communication wall” and “memory wall” bottlenecks through internal high-speed bus interconnections, becoming the optimal solution for large-scale training and inference.
 On the inference side, the rise of AI Agents has also significantly increased token consumption. According to data from the National Bureau of Statistics, by March 2026, China’s daily AI token usage had surpassed 140 trillion, nearly quadrupling from the end of 2025.
On the inference side, the rise of AI Agents has also significantly increased token consumption. According to data from the National Bureau of Statistics, by March 2026, China’s daily AI token usage had surpassed 140 trillion, nearly quadrupling from the end of 2025.
The report cites data indicating that the supernode Blackwell NVL72 generates more tokens per watt compared to the H200 8-card server, significantly leading in inference cost-effectiveness.
Supernodes Win by Volume: Domestic Clusters Overtake
One of the core conclusions of Dongfang Securities’ report is that the supernode architecture provides an effective path for domestic chips to bypass the performance shortfalls of single cards.
For instance, comparing Huawei’s CloudMatrix 384 with NVIDIA’s GB200 NVL72: the BF16 performance of a single Ascend 910C chip is only about one-third of the GB200 module, but through the supernode cluster approach, the total BF16 performance of a single CloudMatrix 384 cluster is 1.7 times that of NVL72, with total memory capacity 3.6 times that of the latter and total memory bandwidth 2.1 times that of NVL72.
The report also points out that the multi-chip solution via Switch tray can effectively compensate for the relatively lagging bandwidth of domestic exchange chips.
According to data cited by Yu Yuan Tan Tian, by 2025, the domestic market share of AI chips in China had reached approximately 41%.
There have also been new developments on the model side—after adapting the DeepSeek-V4 model to Ascend chips, it achieved high throughput and low latency inference deployment; Zhizhu GLM-5 announced deep adaptation with seven mainstream domestic chip platforms.
Dongfang Securities notes that at the interconnection protocol level, the layout of the domestic ecosystem is also accelerating:
- Huawei released and opened the Lingqu (UB) 2.0 technical specification in September 2025, supporting multi-dimensional expansion from cabinet-level to data center-level;
- China Mobile, leading 48 units including Shengke Communication, participated in the OISA Gen2.0 protocol, supporting an increase in AI chip quantity to 1024, with bandwidth exceeding TB/s level;
- Haiguang, Alibaba, and ByteDance have also released self-developed interconnection protocols such as HSL, ALS, and EthLink, continuously enriching the Scale up ecosystem.
Five Major Trends: Clear Paths for Industry Chain Benefits
Dongfang Securities identified five major industrial changes in the supernode era.
First, the demand for exchange chips is rising in both volume and price.
The addition of Scale up domains within supernode cabinets drives a significant increase in the usage of switches and exchange chips.
 For example, with Rubin NVL72, compared to Blackwell, as GPU bandwidth doubles, the number of exchange chips per cabinet increases from 18 to 36.
For example, with Rubin NVL72, compared to Blackwell, as GPU bandwidth doubles, the number of exchange chips per cabinet increases from 18 to 36.
The report also notes that with the expansion of cluster scale and the introduction of secondary HBD domains, the demand for exchange chips may further double.
Second, liquid cooling has become a necessity, with a full liquid cooling era approaching. When the total power consumption of a single cabinet exceeds 50KW, liquid cooling becomes the only option.
 The GB200 NVL72 single cabinet power consumption has reached 120KW, and both Huawei’s CloudMatrix 384 and Alibaba’s Panjiu 2.0 adopt a mixed air-liquid cooling solution.
The GB200 NVL72 single cabinet power consumption has reached 120KW, and both Huawei’s CloudMatrix 384 and Alibaba’s Panjiu 2.0 adopt a mixed air-liquid cooling solution.
The updated generation of the Vera Rubin NVL72 cabinet will officially adopt 100% full liquid cooling, with exchange chip, DPU, optical module, etc., fully equipped with liquid cooling heat dissipation modules, and the cabinet exterior CDU heat dissipation will reach the MW level.
Third, the value of server ODM is being re-evaluated.
Supernode servers elevate manufacturers from past L10-level server assembly delivery to L11 whole cabinet level or even L12 multi-cabinet manufacturing delivery, extending participation from Computer tray to Switch tray, network interconnection, power supply, and cooling system integration, significantly raising the entry threshold.
 Huaqin Technology expects the revenue from supernode projects to exceed 10 billion yuan in 2026; Inspur Information has released the Yuan Nao SD200 supernode, achieving high-speed unified interconnection of 64 domestic AI chips; Baidu’s Kunlun chip 256/512 supernodes will be launched in the first and second half of 2026, respectively.
Huaqin Technology expects the revenue from supernode projects to exceed 10 billion yuan in 2026; Inspur Information has released the Yuan Nao SD200 supernode, achieving high-speed unified interconnection of 64 domestic AI chips; Baidu’s Kunlun chip 256/512 supernodes will be launched in the first and second half of 2026, respectively.
Fourth, the demand for optical interconnections and PCB backplanes is newly added.
High-speed interconnections between computing nodes and exchange nodes prefer copper cables within 64 or 128 XPU scales, with comprehensive costs about half that of optical interconnection solutions.
 Beyond 128 XPU, orthogonal backplane solutions have lower signal loss and more stable structures, suitable for high-density architectures; larger scale supernode clusters will require the introduction of OCS (Optical Circuit Switching) devices to further support Dragonfly+ or 3D Torus topology expansions.
Beyond 128 XPU, orthogonal backplane solutions have lower signal loss and more stable structures, suitable for high-density architectures; larger scale supernode clusters will require the introduction of OCS (Optical Circuit Switching) devices to further support Dragonfly+ or 3D Torus topology expansions.
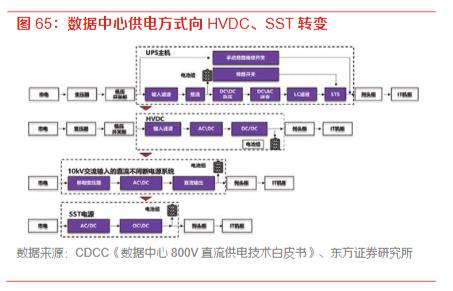
Finally, the restructuring of power supply architecture, with increased demand for PSU and HVDC.
Supernodes adopt a three-level centralized power supply architecture of “room-level high-voltage direct supply → cabinet-level bus transmission → node-level precise step-down,” with PSUs gradually upgrading from 3.3KW to 5.5KW and 18.3KW, corresponding to Powershelf upgrades to 33KW and even 110KW.
As cabinet power levels reach MW, data center power supply architecture is expected to accelerate its transition to high-voltage direct current (HVDC) and solid-state transformers (SST).
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.